The Finalist | YourTutor
E-teacher model that could optimize time and personalized learning. We present a general framework which makes use of technology to improve teachers’ efficiency and optimize students’ time by introducing a personalized self-learning system. Our simulation shows abilities of Reinforcement Learning algorithm to be useful in teaching. A virtual teacher assesses student’s level in a defined area (such as mathematics, literature) by having them solve tasks of defined difficulty and automatically adjusts the difficulty level of following tasks by measuring the time of learning which student needed in order to obtain certain skills. Moreover, by using appropriate measuring functions, the virtual teacher can suggest moving to other areas so that the student does not focus on a single subject.
Project description:
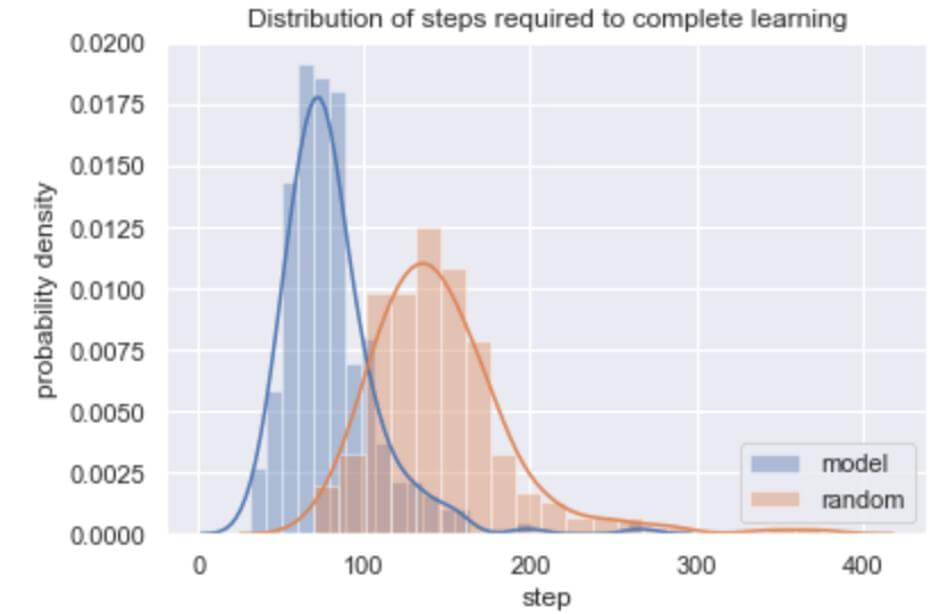
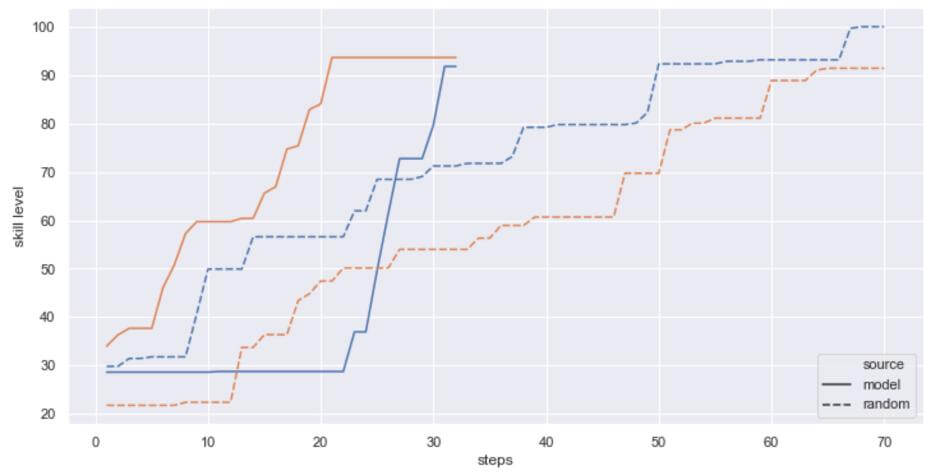
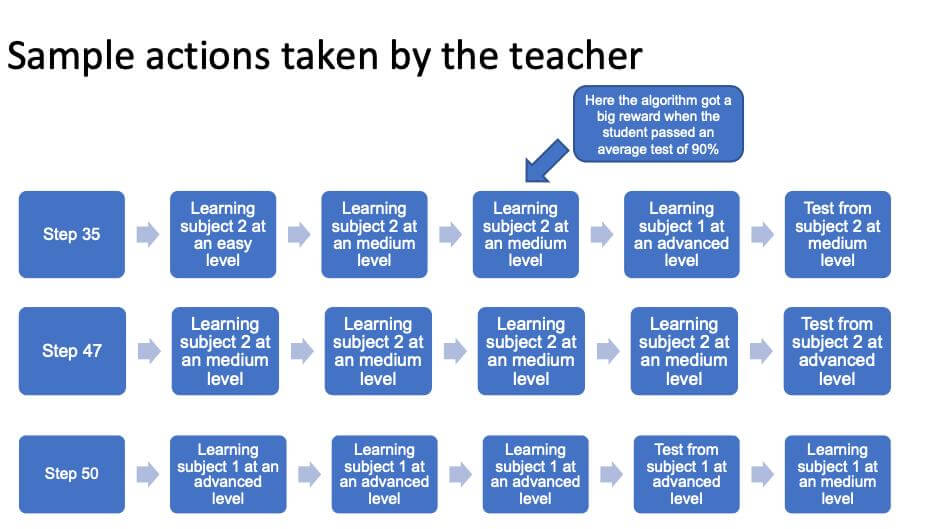
The COVID-19 pandemic resulted in close-down of schools in whole countries, leaving students without teachers and psychological support right before critical exams on their education path, causing stress, anxiety and delay in education. Videoconferences for classes do, in some extent, solve the problem as they allow for conducting classes. However, moving a concept of a group of students listening to a teacher online does not utilize the potential of technology in online learning for schools. We present a general framework which makes use of technology to improve teachers’ efficiency and optimize students’ time by introducing a personalized self-learning system. Our simulation shows abilities of Reinforcement Learning algorithm to be useful in teaching. A virtual teacher assesses student’s level in a defined area (such as mathematics, literature) by having them solve tasks of defined difficulty and automatically adjusts the difficulty level of following tasks by measuring the time of learning which student needed in order to obtain certain skills. Moreover, by using appropriate measuring functions, the virtual teacher can suggest moving to other areas so that the student does not focus on a single subject. In our simulation we use Reinforcement Learning in which an agent representing a teacher, learns itself to make decisions which result in optimized learning of each student. Students are treated as environment with which the agent interacts. They are modeled with randomly sampled expertise and efficiency levels in defined areas, which define their hidden states. It means that one student can be on medium level and improve slowly, while other may start from easy level and improve rapidly. The hidden states are unknown to the teacher. Example of modeling interpretation: Student A has high level of knowledge in mathematics and their test result improves by 1% on average after 30 minutes of learning. During the simulation we observed that as the training progressed, the teacher was making more and more reasonable decisions in regards to its reward strategy. We also performed experiments with reward strategy in which the teacher gets no reward for learning – after some time it realised it has to pay the price of learning to achieve success in testing! Simulation was performed using Open AI Gym environment, with code in Keras and usage of Reinforcement Learning: Proximal Policy Optimization 2 and Trust Region Policy Optimization.
Team name: BrAIn Power
Project name: YourTutor
Team members: Ewa Juralewicz, Kamil Jędryczek, Michał Augoff, Konrad Fuchsig, Kamil Zawistowski, Mateusz Szczepański
YourTutor
Media: